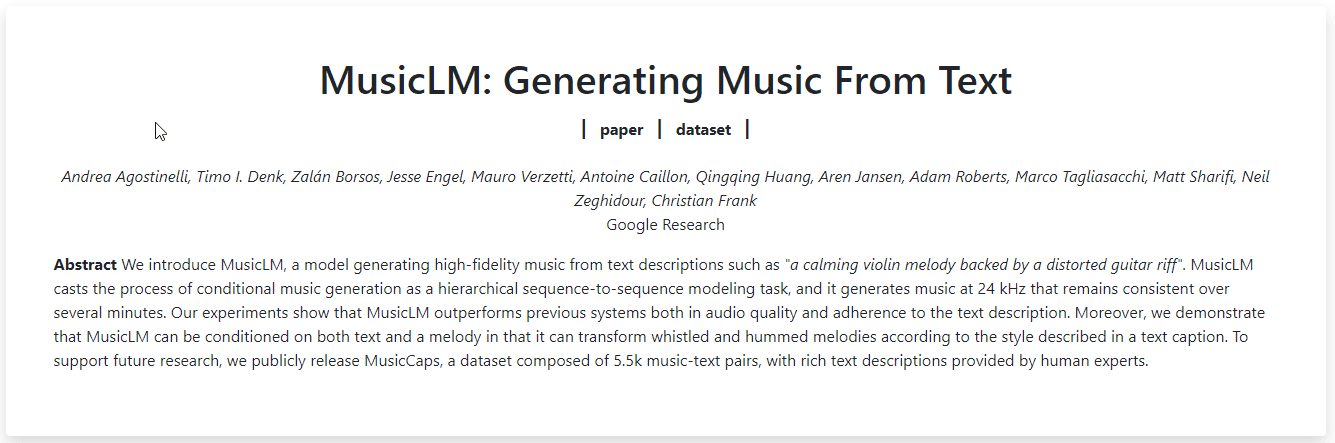
What is MusicLM?
The MusicLM tool is a model for generating high-fidelity music from text descriptions. The model is a hierarchical sequence-to-sequence modeling task that generates music at 24 kHz that remains consistent over several minutes. The tool can condition the generated music on both text and melody, allowing it to transform whistled and hummed melodies according to the style described in a text caption. The tool is also capable of generating music from painting descriptions, instruments, genres, musician experience levels, places, and epochs. Additionally, the tool is able to generate diverse versions of the same text prompt and the same semantic tokens.